
Early in my teaching career, I used to begin a course on databases by asking students how much data they thought a mid-sized hospital generated in a single day. The answers were invariably anchored to the world they knew — a few gigabytes, perhaps. The honest answer, even then, was in the terabytes: imaging files, electronic health records, sensor data from monitoring equipment, billing transactions, laboratory results. Today, that same hospital may generate those volumes in hours.
I share that recollection not for dramatic effect, but because it captures something genuine about the challenge that data engineering exists to solve. The data is there — voluminous, heterogeneous, generated at speed, and latent with analytical value. The question is whether the infrastructure exists to collect it reliably, store it efficiently, transform it purposefully, and make it available to the systems that can extract meaning from it. That infrastructure is what data engineers design and build. And in the decade I have spent watching this discipline mature from a specialised sub-field into a foundational pillar of modern computing, I have come to regard it as one of the most consequential engineering domains of our time.
This piece examines what data engineering actually involves, how modern analytics platforms are architectured, why big data is the essential substrate on which artificial intelligence operates, and what a rigorous graduate-level education in this space develops that practice alone cannot provide.
Table of Contents
- Data Engineering: A Discipline in Its Own Right
- The Architecture of Modern Analytics Platforms
- Big Data: The Essential Substrate of Artificial Intelligence
- What a Big Data MTech Course Structure Actually Develops
- The Professional Landscape: Where Data Engineers Work and What They Shape
- Who Is This Education For — and What Readiness Looks Like
- FREQUENTLY ASKED QUESTIONS
Data Engineering: A Discipline in Its Own Right
There is a persistent tendency to conflate data engineering with data science — to treat the data engineer as a support role, laying pipes so that data scientists can do the interesting work. This framing is inaccurate, and it understates the technical complexity and strategic importance of the discipline.
Data engineering is the design, construction, and maintenance of the systems that move data from its point of origin to the point of use. It encompasses the ingestion of raw data from diverse sources — databases, APIs, event streams, IoT sensors, log files, third-party feeds — the transformation of that data into forms suitable for analysis, the orchestration of processing pipelines that operate reliably at scale, and the governance of data quality, lineage, and access control across the entire lifecycle.
What makes data engineering demanding is not any single technical problem but the combination of constraints it must satisfy simultaneously. A production data pipeline must be correct — transformations must preserve data integrity without introducing errors. It must be reliable — failures must be detected, logged, and recovered from without data loss. It must be scalable — it must handle both typical loads and peak volumes without redesign. And it must be maintainable — the engineers who inherit a pipeline must be able to understand, modify, and extend it without heroic effort. Satisfying all four constraints in systems processing billions of events per day is a genuinely difficult engineering problem.
"Educator's Observation: The students who struggle most with data engineering are not those with weaker programming skills. They are those who underestimate the discipline's systems-thinking demands — the need to reason simultaneously about throughput, fault tolerance, consistency, and cost."
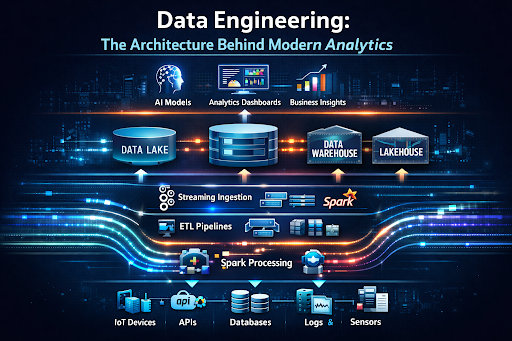
The Architecture of Modern Analytics Platforms
Understanding modern analytics architecture requires looking at how the field has evolved — because the architecture of today's platforms reflects lessons learned from the limitations of earlier approaches.
The Data Warehouse Era
For much of enterprise computing history, the analytics platform of choice was the
relational data warehouse: a structured repository, carefully schema-designed,
populated by batch ETL (extract, transform, load) processes, and optimised for
SQL-based reporting and business intelligence. Systems like Teradata, Oracle, and
later Amazon Redshift and Google BigQuery represent this paradigm. The data warehouse
excels when data is structured, schemas are stable, and the primary use case is
aggregated reporting. Its limitations become apparent when data is unstructured or
semi-structured, when schemas evolve rapidly, or when the volume and velocity of
incoming data exceed what batch ingestion can handle.
The Data Lake
The data lake emerged as a response to these limitations. Rather than imposing
structure at ingestion time, a data lake stores raw data in its native format —
structured tables, JSON documents, images, video, log files — on distributed storage
systems such as Hadoop HDFS or, increasingly, cloud object stores like Amazon S3,
Azure Data Lake Storage, or Google Cloud Storage. The schema is applied at read time
rather than write time, a pattern known as schema-on-read, which provides flexibility
but places the burden of data quality and consistency management on the consuming
application.
Data lakes solved the volume and variety problem but introduced new challenges. Without careful governance, they became what practitioners began calling data swamps: repositories of raw data that were difficult to navigate, inconsistently formatted, and of uncertain quality. The metadata management, data cataloguing, and access control mechanisms required to make a data lake genuinely useful were non-trivial to implement and maintain.
The Lakehouse Architecture
The lakehouse represents the current state of the art - an architecture that combines
the flexibility and cost-efficiency of data lake storage with the reliability,
governance, and performance optimisation of the data warehouse. Technologies such as
Delta Lake, Apache Iceberg, and Apache Hudi provide ACID transaction semantics on top
of object store-based storage, enabling data versioning, schema enforcement, and
efficient upsert operations that were previously only possible in dedicated warehouse
systems. Platforms such as Databricks and Snowflake have built commercial products
around this paradigm, and it has become the dominant pattern for organisations
building net-new analytics infrastructure.
The Streaming Layer
Cutting across all of these storage paradigms is the streaming layer — the
infrastructure for processing data in real time as it arrives, rather than in periodic
batches. Apache Kafka has become the de facto standard for high-throughput event
streaming, providing a durable, distributed log that decouples data producers from
consumers. Stream processing frameworks such as Apache Flink and Spark Structured
Streaming allow complex transformations, aggregations, and joins to be performed on
data in motion, enabling use cases — fraud detection, real-time personalisation,
industrial monitoring — that batch processing fundamentally cannot support.
The Modern Data Stack and Orchestration
The modern data stack, as it has come to be known, is an ecosystem of specialised
tools that handle different aspects of the data engineering workflow. DBT (data build
tool) has become the standard for transformation within the warehouse, bringing
software engineering practices — version control, testing, documentation, modular
composition — to what was previously ad hoc SQL scripting. Apache Airflow and its
successors provide workflow orchestration, allowing complex pipeline dependencies to
be defined, scheduled, and monitored. Data catalogues such as Apache Atlas and
commercial equivalents provide the metadata management layer that makes large data
ecosystems navigable.
"Architecture Principle: Modern analytics platforms are not single systems — they are ecosystems of composable, specialised tools. The data engineer's skill is not mastery of any one tool but the judgement to compose them appropriately for a given set of requirements and constraints."
Big Data: The Essential Substrate of Artificial Intelligence
The relationship between big data and artificial intelligence is architectural, not incidental. Modern AI systems — particularly the deep learning models that have driven the most visible advances of the past decade — are fundamentally data-hungry. Their performance scales with the quality and quantity of the training data they receive, and the infrastructure required to curate, store, version, and serve that data at scale is data engineering infrastructure.
This relationship manifests in several specific ways that practitioners must understand.
Feature Engineering and Feature Stores
Before a machine learning model can be trained, raw data must be transformed into
features — numerical representations that capture the patterns relevant to the
prediction task. This transformation process, feature engineering, is one of the most
labour-intensive and consequential steps in the ML workflow, and it is fundamentally a
data engineering problem. The feature store — a system that computes, stores, and
serves features consistently between training and production — has emerged as a
critical piece of ML infrastructure precisely because the absence of one leads to one
of the most common failure modes in deployed AI systems: training-serving skew, where
the data a model sees in production differs subtly from what it was trained on.
Data Quality and Model Reliability
The principle that the quality of a machine learning model's outputs is bounded by the
quality of its inputs is not merely a theoretical observation; it is the leading
practical cause of AI system failure in production. Inconsistent labelling, missing
values, distribution shift over time, and undocumented data transformations all
degrade model performance in ways that are often difficult to diagnose. Data
engineering practices — schema validation, data quality monitoring, pipeline testing,
and data lineage tracking — are the mechanisms by which these failure modes are
prevented. An organisation with strong data engineering capability builds more
reliable AI systems, not because its data scientists are more talented, but because
the data infrastructure they work with is more trustworthy.
Blockchain Technology and Data Integrity
As organisations manage increasingly sensitive and high-stakes data — healthcare
records, financial transactions, supply chain provenance, regulatory compliance data —
the question of data integrity and auditability has become central to data
architecture. Distributed ledger technologies, underpinning what is more broadly
understood as blockchain
technology, offer a cryptographically secured, append-only
record of data transactions that is independently verifiable without reliance on a
central authority.
In the context of analytics platforms, blockchain-based approaches are being applied to data provenance — maintaining an immutable audit trail of where data originated, how it was transformed, and who accessed it. This is particularly significant in regulated industries where data lineage is a compliance requirement, and in multi-party data sharing arrangements where no single organisation has the trust authority to serve as a central record-keeper. A Master's in blockchain technology that engages seriously with data engineering contexts equips graduates to address these challenges precisely: designing systems where trust is cryptographically enforced rather than institutionally assumed.
The Data Pipeline as AI Infrastructure
When I speak with organisations that have struggled to move AI from proof-of-concept
to production, the bottleneck is almost never the model. It is the pipeline. The data
collection, transformation, validation, and serving infrastructure that a model
depends on in production is almost always more complex, more fragile, and more
expensive to maintain than the model itself. This is why organisations that invest in
data engineering maturity — building reliable, observable, well-tested pipelines —
consistently achieve better AI outcomes than those that treat data infrastructure as
an afterthought. The big
data engineering course that addresses this reality is not
teaching students to use tools; it is teaching them to think architecturally about the
relationship between data systems and intelligent systems.
What a Big Data MTech Course Structure Actually Develops
For prospective learners evaluating a Big Data MTech course structure, the question is not simply what topics are covered but what capabilities are systematically developed and how they compound over the duration of the programme.
A rigorous postgraduate programme in this space develops capabilities across several layers that self-directed learning consistently fails to integrate.
- Foundational Systems Thinking
Before any specific technology is introduced, a well-structured programme develops the ability to reason about distributed systems: how data is partitioned and replicated, what consistency guarantees different architectures provide, how failures propagate and are contained, and what the performance implications of different architectural choices are. This foundational layer is what allows a graduate to evaluate a new tool or framework on its merits rather than adopting it on the basis of current popularity. - The Full Data Engineering Lifecycle
A comprehensive programme addresses the complete arc from data ingestion through storage, processing, governance, and serving — not as a survey of technologies but as an integrated view of how these components interact in production systems. Students who engage with the full lifecycle develop the systems-level perspective that distinguishes a data platform architect from a pipeline developer. - Scalable Processing Frameworks
Hands-on depth with Apache Spark, Kafka, Flink, and the cloud-native equivalents from AWS, Azure, and GCP is not optional for a credible programme. But more important than tool fluency is the ability to reason about performance, partitioning, and fault tolerance within these frameworks — to know not just how to use them, but when each is appropriate and what trade-offs each entails. - Data Governance and Quality Engineering
This is the area most frequently underdeveloped in industry training and most consistently valued by senior hiring managers. Schema management, data contracts, quality monitoring, lineage tracking, and access control are the engineering disciplines that determine whether a data platform remains trustworthy as it scales. A programme that treats governance as an afterthought rather than a first-class design concern is not preparing graduates for the realities of enterprise data engineering. - Emerging Paradigms: Blockchain, Federated Learning, and Data
Mesh
A forward-looking curriculum engages seriously with architectural paradigms that are moving from research into practice. Blockchain technology MTech course content that addresses distributed ledger architectures in the context of data provenance and multi-party analytics prepares graduates for domains — financial services, healthcare, supply chain — where these approaches are already being deployed. The data mesh paradigm — which reframes data platform architecture around domain ownership and self-serve infrastructure — represents a significant organisational and technical shift that graduates will encounter in the organisations they join or build.
"Curriculum Perspective: The best data engineering programmes I have observed treat technology as the medium and systems thinking as the message. Graduates who leave with conceptual frameworks — not just tool fluency — are the ones who remain valuable as the technology landscape continues to evolve."
The Professional Landscape: Where Data Engineers Work and What They Shape
The demand for data engineering expertise is, at this point, one of the most consistent signals in the technology labour market. Every organisation that generates data — which is to say, every organisation — faces the challenge of making that data useful, and the gap between the data they collect and the intelligence they extract from it is almost always an infrastructure problem as much as an algorithmic one.
In financial services, data engineers build the pipelines that feed risk models, fraud detection systems, and regulatory reporting infrastructure. The correctness and latency of these pipelines have direct financial consequences. In healthcare, they design the systems that integrate data from electronic health records, imaging systems, wearables, and genomic databases — data that is as sensitive as any in existence and as consequential as any in its potential analytical value. In retail and e-commerce, they maintain the real-time personalisation and inventory optimisation infrastructure that operates at transaction scale. In manufacturing, they build the industrial IoT data platforms that enable predictive maintenance and quality control.
The seniority progression in data engineering is well-defined and financially rewarding. Junior data engineers build and maintain pipelines under guidance. Mid-level engineers own platform components and contribute to architectural decisions. Senior engineers and staff engineers design platform architectures, define engineering standards, and lead the technical direction of data teams. Principal engineers and architects shape data strategy at the organisational level, often working directly with product and business leadership.
What I observe consistently, in the graduates I remain in contact with, is that the professionals who advance most rapidly are those who combine technical depth with the ability to communicate the business implications of data architecture decisions — who can explain to a non-technical stakeholder why investing in data quality infrastructure now will reduce the cost of AI deployment later. That communication capability is not independent of technical depth; it grows from it. You cannot explain the implications of technical choices you do not fully understand.
Who Is This Education For — and What Readiness Looks Like
The question of readiness for a Big Data MTech course is one I am asked frequently, and I want to answer it honestly rather than generically.
The programme is designed for professionals with an engineering or computer science foundation — not necessarily in data engineering, but with sufficient programming fluency and systems exposure to engage with the curriculum's technical demands from the outset. A background in software development, database administration, systems engineering, or analytics provides a strong entry point. Mathematical maturity — comfort with probability and statistics at the level required for understanding ML fundamentals — is useful but not a hard prerequisite for the data engineering curriculum.
What matters as much as prior knowledge is orientation. The learners who thrive in rigorous data engineering programmes are those who approach systems as puzzles to be understood rather than tools to be operated — who are curious about why a system behaves as it does under load, not just how to make it function in the happy path. That orientation is difficult to teach directly, but it is clearly observable in the learners who arrive with it, and it is the single best predictor of the depth of understanding they develop.
For working professionals — who constitute the majority of those pursuing an MTech online or through executive formats — the advantage of bringing live professional context to the learning experience is real. A module on pipeline orchestration carries a different weight when the learner is managing a production pipeline whose failures have organisational consequences. The challenge is ensuring that professional experience enriches learning rather than constraining it — that existing patterns of practice are interrogated and refined, not simply validated.